1. Definition
Die Datenmodellierung ist der Prozess der Darstellung von Informationen und Beziehungen zwischen Daten in einer organisierten Struktur.
Hierbei ist das Modellieren der Daten die Grundlage für die Konstruktion einer Datenbank. Es hilft dabei, komplexe Informationen in leicht verständliche Form zu organisieren.
2. Grundlagen der Datenmodellierung
2.1. Entitäten
Eine Entität ist ein eindeutig definierbares Objekt in der Wirklichkeit.
z.B: Schüler
2.2. Attribute
Attribute beschreiben Merkmale oder Eigenschaften einer Entität.
Beispiel:
für die Entität Schüler lassen sich folgende Attribute bestimmen:
-
Schüler_ID
-
Nachname
-
Vorname
-
usw.
2.3. Beziehungen
Eine Beziehung assoziiert wechselseitig zwei (oder mehrere) Entitäten. Assoziation bedeutet, dass eine Entität eine andere Entität kennt und mit ihr in Wechselwirkung steht
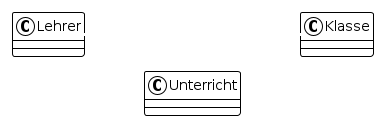
2.3.1. Kardinalität von Beziehungen
Die Kardinalität einer Beziehung gibt an, wie viele Entitäten der einen Entitätsmenge einer beliebigen Entität der anderen Entitätsmenge zugeordnet sein können.




4. Relationales Modell (RM)
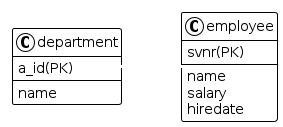
department(a_id, name)
employee(svnr, d e p t, name, salary, hiredate)
INFO: Bei "dept" muss die Linie strichliert werden (ohne Leerzeichen)!
5. Wichtige Punkte bei der Datenmodellierung
5.1. Gut durchdachte Datenmodellierung
-
strukturierte Speicherung der Daten
-
Vermeidung von Redundanz
-
Integrität der Daten
-
Flexibilität und Skalierbarkeit
5.2. Die 3 Stadien der Datenmodellierung
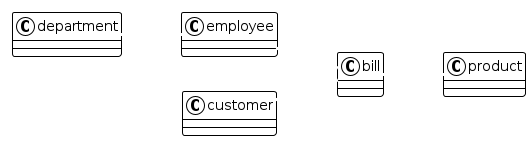
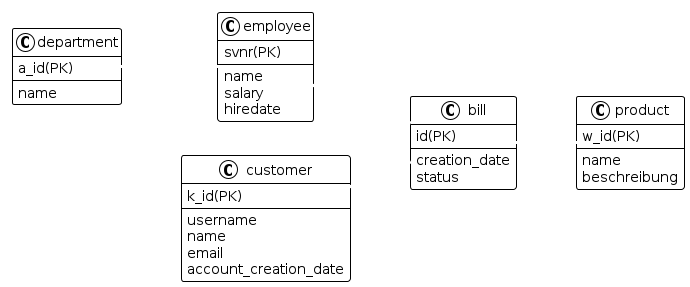
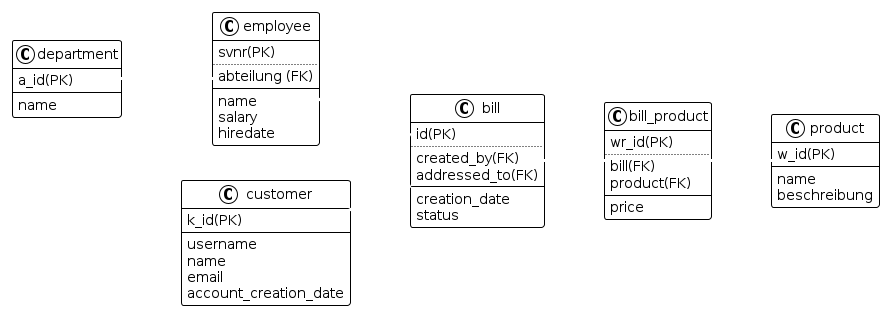
5.2.3. Physisches Modell:
Eigentliche Implementierung in der gegebenen Datenbank (Abbildung der Tabellenstruktur wie auf der DB)
Dieses Modell wird verwendet, um Besonderheiten einer Implementierung nachvollziehen zu können. Je besser man diese Versteht, desto weniger Komplikationen können bei der Umsetzung geschehen. (Quelle)
6. Normalisierung
Ziele der Normalisierung:
-
Redundanz minimieren
-
Integrität der Daten
-
Verhindert Anomalien
Deswegen ist es wichtig diese im Schlaf zu können. Denn dadurch könne dieses Beispiel einträten:
Frau Maier heiratet und nimmt den Namen ihres Mannes an. Dadurch muss in der Datenbank der Name an mehreren Stellen geändert werden, wenn man sich nicht an die Normalisierungen hält.
Hierbei gibt es mehrere Normalformen:
6.1. Erste Normalform
Tumfart Kurzfasssung
Atomar
Eine Relation befindet sich in erster Normalform, wenn alle Attribute nur einfache Attributwerte aufweisen. ⇒
Alle Attribute sind Atomar
Hierbei muss jedes Attribut in die kleinste mögliche Einheit umgewandelt werden:
Adresse ⇒ Straßenname, Hausnummer, Postleitzahl, Stadt
Bsp:
SchülerNr |
Name |
Vorname |
Klasse |
Klassenlehrer |
Fach |
FachLehrer |
Zeit in h |
1 |
Jürgens |
Ina |
11a |
Lempel |
Tanz |
Reiter |
1.5 |
2 |
Schmidt |
Tom |
12a |
Breier |
Chor |
Stütz |
3.8 |
Hierbei nimmt die Redundanz zu, wenn z.B. die Klasse, der Klassenlehrer oder das Fach gleich ist.
Wenn nun sich z.B. der Name des Lehrers ändert, muss dieser in vielen einträgen aktualisiert werden.
6.2. Zweite Normalform
Tumfart Kurzfasssung
nicht Schlüsselattribute nicht funktional
Eine Relation befindet sich in zweiten Normalform, wenn
-
Diese sich nicht in der 1. Normalform befindet
-
jedes Nicht-Schlüssel-Attribut vom Primärschlüssel voll funktional abhängig ist.
Schritte zur herstellung der 2. Normalform:
-
Primärschlüssel der gegebenen Relation festlegen, falls dieser nur aus einem Attribut besteht, so liegt bereits 2. NF vor.
-
Untersuchung, ob aus Teilschlüsselattributen bereits weitere Attribute folgen. Falls nicht, liegt bereits die 2. NF vor. Falls Abhängigkeiten gefunden werden, dann
-
Neue Relation bilden, die das Teilschlüsselattribut und alle von diesem abhängigen Nichtschlüsselattribute enthalten. Das Teilschlüsselattribut wird in der neuen Relation der Primärschlüssel.
-
Löschen der ausgelagerten Nichtschlüsselattribute in der Ausgangsrelation.
-
Vorgang ab 2. wiederholen, bis alle Nichtschlüsselattribute vom gesamten Schlüssel funktional abhängig sind.
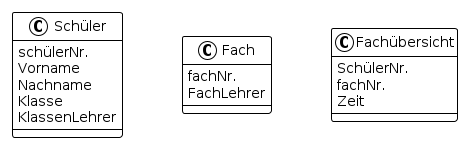
Beispiel:
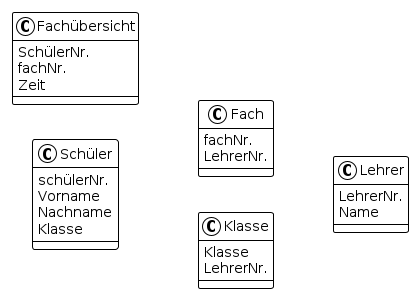
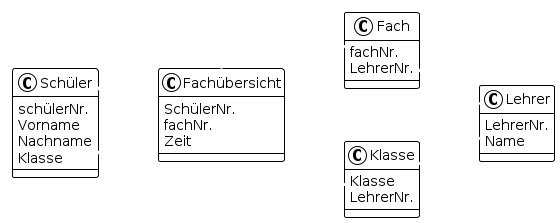
Aus dem Fach lässt sich bereits eindeutig auf einen Namen dieses schließen.
Aus der Schülernummer lässt sich eindeutig auf Name, Vorname, Klasse und Klassenlehrer schließen.
Somit sind zwei neue Relationsschemas Fach und Schüler zu erzeugen und das verbleibende Schema Fach so zu überarbeiten, dass die Attribute Beschreibung, Name, Vorname, Klasse und Klassenlehrer gelöscht werden
6.3. Dritte Normalform
Tumfart Kurzfasssung
nicht Schlüsselattribute nicht funktional
Eine Relation befindet sich in 3. Normalform, wenn:
-
sie in der zweiten Normalform ist und
-
jedes Nichtschlüsselattribute nicht transitiv vom Primärschlüssel abhängig ist, d.h. aus keinem Nichtschlüsselattribut folgt ein anderes Nichtschlüsselattribut.
Regel zum Prüfen der zweiten Bedingung: Wenn aus einem Nichtschlüsselattribut ein anderes Nichtschlüsselattribut folgt, dann liegt keine 3. Normalform vor!
Schrittfolge zur Herstellung der dritten Normalform:
-
Untersuchung, ob aus Nichtschlüsselattributen andere Nichtschlüsselattribute folgen. Falls nicht, liegt bereits die 3. NF vor. Falls Abhängigkeiten gefunden werden, dann
-
Neue Relation bilden, die das Nichtschlüsselattribut (wird nun Primärschlüssel der neuen Relation) und die von ihm abhängigen Attribute enthält.
-
Löschen der ausgelagerten Nichtschlüsselattribute mit Ausnahme des Attributes, das in der neuen Relation Primärschlüssel ist.
-
Vorgang ab 2. wiederholen, bis keine Abhängigkeiten mehr bestehen
7. Namensvergebung von Entitäten
-
Im Singular
-
keine Abkürzungen
-
Konsistent
-
keine Synonyme
-
keine Homonyme
8. Relationale Datenbanken
-
Oracle DB
-
Microsoft SQL Server
-
PostgresSQL
-
Derby DB
-
Maria DB
-
MySQL
-
SqlLite
10. Fragen von Tumfart
Was passiert, wenn man eine Redundanz hat?
Anomalie
Welche Datenbanken gibt es?
Relational, NoSQL
Gibt es verschiedene Hersteller?
Oracle, SQL Server, Maria DB, MySQL, SQL Light
Relationale Datenbanken
-
Oracle DB
-
Microsoft SQL Server
-
PostgresSQL
-
Derby DB
-
Maria DB
-
MySQL
-
SqlLite
NoSQL Datenbanken
-
Mongo DB
-
Redis
-
Apache Cassandra
-
Neo4j
Welche Notationen gibt es?
MC, UML, Krähenfuß
Wer verwendet die Krähenfuß-Notation?
Oracle
Wie heißt das Tool für die Datenmodellierung?
Data Modeller
Wann löst man eine Aggregationstabelle?
Im ERD (Entity Relationship Diagramm) oder RM (Relationen Modell)
Was macht man im Relationen Modell?
Man definiert die Attribute und die PK (Primary Key) und die FK (Forign Keys)