1. Oracle Server Architecture
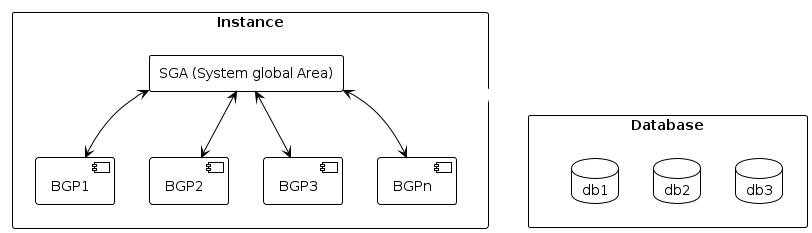
Eine Oracle DB besteht aus einem Datenbankserver, und einer oder mehreren Datenbankinstanzen.
Eine Instanz besteht aus mehreren Hintergrundprozessen.
Jedes Mal, wenn eine Instanz gestartet, ein geteilter Memory Space in der SGA (System Global Area) angelegt.
Die SGA beinhaltet Daten- und Kontrollinformationen für die einzelnen Datenbankinstanzen.
Die Hintergrundprozesse beinhalten Funktionen zur synchronisationen und überwachungsprozesse für die einzelnen Datenbankinstanzen.
Diese laufen viel parallel, um die Performance der Datenbank zu optimieren.
Die Datenbank besteht aus physischen und logischen Dateien, hierauf wird noch später eingegangen.
2. Connection to Oracle DB
Jeder Nutzer, der sich mit der Oracle DB verbindet, bekommt einen eigenen Benutzerprozess. Der Code des jeweiligen Benutzers wird über sogenannte "client foreground processes" gehandhabt. Um SQL Statements der jeweiligen Benutzer auszuführen, wird ein sogenannter "server process" erstellt.
Eine Connection is das Verbindungsstück zwischen Benutzer und Datenbank. Diese Prozesse können auf eigenen Servern laufen, um die Performance auf großen Datenbanken zu verbessern.
Die Verbindung repräsentiert auch einen validen Login für die Datenbank. Wenn sich ein User mit der Datenbank verbindet, muss er einen validen Account und ein valides Passwort vorweisen.
3. Oracle DB Memory Structures
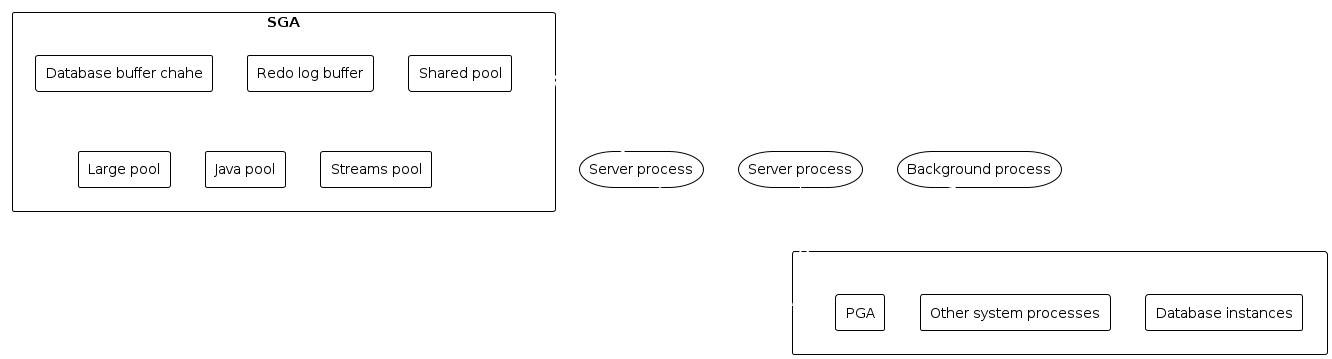
Es gibt 2 grundlegende Prozesse, die mit einer Instanz verbunden werden:
3.1. SGA
SGA = System Global Area
Die System Global Area wird von allen Server und Prozessen geteilt. Die SGA beinhaltet folgende Datenstrukturen:
-
Database buffer cache: speichert Blöcke als cache zwischen.
-
Redo log buffer: speichert wiederherstellungsinformationen, bevor diese in die DB gespeichert werden.
-
Shared pool: speichert verschiedenste Strukturen zwischen, die zwischen den Instanzen verwendet werden können
-
Large Pool: optionale Verwendung für spezielle operation, wie etwa backup oder I/O server prozesse
-
Java pool: Benutzt für session spezifischen Java code, oder Daten in der jvm
-
Streams pool: Benutzt von Oracle Streams
4. Database Buffer Cache
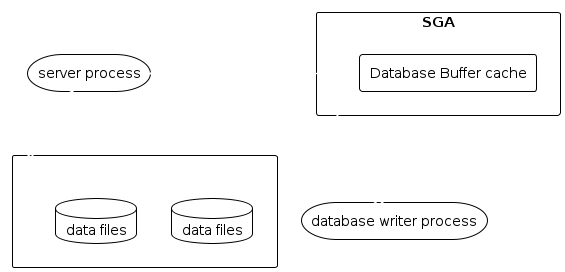
The Data Buffer Cache beinhaltet Blöcke, die gerade von der Datenbank gelesen wurden.
Bevor also eine Abfragt von der Datenbank abgefragt wird, wird zuerst im Data Buffer cache nachgeschaut, ob diese Abfragte nicht bereits zwischengespeichert wurde.
Wenn die Daten nicht im Buffer cache gefunden wurden (cache miss),
dann müssen diese zuerst in diesen kopiert werden, bevor der Prozess diese erhält. Dies führt dazu, dass alle Blöcke, die die Datenbank benötigt, immer im Buffer cache vorhanden sein müssen. (Bei größeren Abfragen werden die nicht mehr benötigten Blöcke aus dem Buffer cache gelöscht).
Die Puffer werden von einem Prozess verwaltet. Die Puffer beinhalten eine Mischung aus zuletzt abgefragten Blöcken, wie auch Blöcke, die sehr oft verwendet werden.
5. Redo Log Buffer
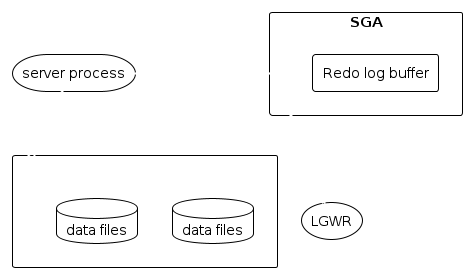
LGWR = Log writer (process)
Im Redo log buffer stehen Informationen zu Änderungen in der Datenbank. Dieser beinhaltet Informationen, die Datenänderungen auf der Datenbank rekonstruieren können. Folgende Statements verursachen Einträge im redo log:
-
INSERT
-
UPDATE
-
DELETE
-
CREATE
-
ALTER
-
DROP
Redo Einträge werden verwendet, um die Datenbank im Falle eines Absturzes wieder zu starten. Die Redo Log buffers haben immer eine fix festgelegte Größe im SGA. Wird der Redo Log voll, oder nach einem konfigurierbaren Zeitintervall werden Checkpoints erstellt. Diese leeren den Redo log.
Der Redo Log Writer schreibt die Redo Logs in die dafür vorgesehenen Redo log files. Dies passiert mit nur wenig caching, um im Falle von z.B eines Stromausfalles nur so wenig Information wie möglich zu verlieren. Wie viele dieser Log Writer es gibt, hängt ab von der Größe der Datenbank. Die Anzahl wird automatisch von der Datenbank verwaltet. Es muss allerdings immer mindestendes ein Redo Log writer vorhanden sein.
6. Shared Pool
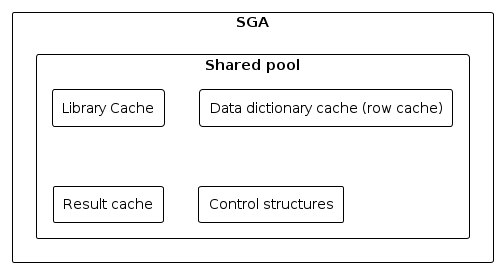
Der Shared Pool ist Teil des SGA. Dieser beinhaltet folgende Strukturen:
6.1. Library Cache
Der Library Cache beinhaltet Teile von SQL Statements, welche mit anderen SQL Statements geteilt werden können (Sub-queries, etc.). Weiters enthält dieser PL/SQL Prozeduren und Packages. Zuletzt ist dieser auch dafür zuständig, Locks und Kontrollstrukturen zwischenzuspeichern.
6.2. Data Dictionary
Das Data Dictionary ist eine Reihe von Tabellen, welche Referenzinformationen anderen Tabellen in der Datenbank halten. Das Data dictionary wird so oft von Oracle verwendet, dass es sogar 2 Teilbereiche des Arbeitsspeichers ihm zugeschrieben werden.
Der erste dieser Teilbereiche heißt Data dictionary cache, oder auch row cache, der zweite ist der Library cache. Alle Prozesse in der Oracle Datenbank verwenden diese 2 Caches, um Data Dictionary Informationen zu erhalten.
7. Large Pool
Der Large Pool erlaubt es, verschiedenste Daten, die nicht in die anderen Pool gehören, oder zu groß für die anderen Poll sind, zu speichern.
Dieser beinhaltet:
-
Session speicher für shared server und Oracle XA interface
-
Parallele Ausführungspuffer
-
I/O Server Prozesse
-
Backup & Restore Prozesse
Optionale Inhalte:
-
Parallele Ausführung
-
Recovery Manager
-
Shared server
Der Pool wird aber großteils dafür verwendet, SQL & PL/SQL Statements zu cachen.
8. Java Pool und Streams Pool
Der Java Pool wird verwendet, um spezifischen Java Code für die Sessions und die dazugehörige JVM.
Der Streaming-Pool wird vor allem verwendet um:
-
Gepufferte Queue Nachrichten zu speichern
-
Arbeitsspeicher für Oracle Streaming Prozesse zu schaffen.
Genauere Details zu diesen würden den Rahmen sprengen.
9. Verteilung der Hintergrundprozesse
9.1. DBWn (Database Writer process)
Der Database Writer prozess schreibt abgeänderte (dirty) Blöcke vom Database buffer in die jeweiligen Database files. Dies passiert Asynchron
9.2. LGWR (Log writer process)
Schreibt recovery Informationen vom log buffer zum log file auf der Festplatte
9.3. CKPT (Checkpoint process)
Schreibt Checkpoint inforationen in die Control Dateien und in jeden data file header
9.4. SMON (System Monitor process)
Führt den Recovery Prozess bei Systemstart aus und löscht temporäre, unbenutze Segmente
9.5. PMON (Process Monitor process)
Führt eine Prozess-Recovery durch, wenn ein Benutzerprozess fehlschlägt.