1. Indices
Indices dienen schnelleren Abfragen. Hierbei können Spalten, die Unique sind, indexiert werden. Falls die Spalte aber nicht Unique ist, ist ein großer Wertebereich empfohlen. Es gibt 2 Arten für Indices:
1.1. BTREE Index
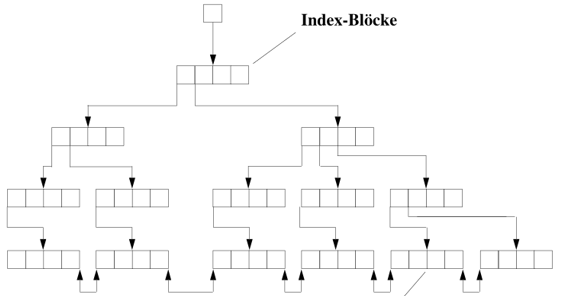
| BTREE = Balanced Tree |
-
besonders gut, wenn es in einer Spalte viele UNIQUE Werte gibt.
-
Nicht für NULL-Werte geeignet
-
Verwendet Balanced Tree, daher O(log(n))
1.2. Nicht berücksichtige Indices
Die SQL Statements für einen BTREE müssen so geschrieben werden, dass der SQL Compiler den BTREE auch verwenden kann:
Beispiele
WHERE SAL <> 0WHERE SAL > 0WHERE UPPER(EName) = 'JEFF'WHERE EName = 'jeff'1.3. Bitmap Index
Der Bitmap Index eignet sich besonders gut für Werte, welche nicht Unique sind. Ein Beispiel hierfür währe das Geschlecht. Der Bitmap Index berücksichtigt NULL Werte. Ebenfalls ist dieser besonders gut für Queries, die einen ungleich Operator beinhalten. Des Weiteren eignet er sich gut für COUNT(*). Allerdings gibt es immer wieder Probleme bei Locking.
2. Optimizers
Die Hauptaufgabe bei Optimizer ist, Pläne zu erstellen, wie eine Query ausgeführt werden sollte. Hierbei ist vor allem wichtig, dass die Pläne so erstellt werden, dass diese möglichst effizient ausgeführt werden kann. Hierbei ist wichtig, dass die gesamte Ausführzeit minimiert wird. Die Zeit, um den ersten Treffer zu finden ist hierbei allerdings unwichtig.
Es gibt 2 Arten von Optimizers:
-
Rule Based Optimizer (RBO)
-
Cost Based Optimizer (CBO)
2.1. Zugriffsmethoden von Optimizer
-
Full Table Scan: Jede Zeile wird angeschaut
-
Index Scan: Ein Index wird verwendet
Full Table Scans in Oracle sind besonders effizient, da die Datenbank viele optimierungen für das Auslesen von vollen Tabellen hat. Ein Beispiel hierfür ist, dass die Datenbank die Anzahl von etwas bereits beim Lesen der Blöcke bestimmen kann. Dies bedeutet, dass beim Zählen aller Einträge in einer Tabelle die Blöcke zwar gelesen werden, allerdings nicht im DB System weiter verwendet werden.
2.2. Rule Based Optimizer (RBO)
Der RBO versucht, Full Scans möglichst zu vermeiden. Hierbei schaut er sich eine gegebene Query an, und probiert diese zu beschleunigen. Falls dieses allerdings mit den festgelegten Regel nicht möglich ist, wird ein Full Table Scan verwendet.
2.3. Cost Based Optimizer (CBO)
Benutzt Analysen und Statistik, die im Data Dictionary gespeichert werden, um den Ausführungsplan zu erstellen. Dabei betrachtet dieser die Anzahl von Reihen und Spalten, die Selektivität der Werte, und auch ob ein Index die Performance einer Query beschleunigen kann.
-
Full Table Scans sind hierbei erlaubt
-
CBO kann SQL Queries umschreiben
Den Ausführungsplan kann man sich mithilfe folgendem SQL Statements anschauen:
EXPLAIN PLAN FOR SELECT * FROM EMP WHERE JOB LIKE 'CLERK'2.4. Analyze Befehl
Mit dem Analyze Befehl können Statistiken für Tabellen, die Spalten der Tabellen, wie auch von Views und Indices analysiert werden.
select * from ALL_TAB_COL_STATISTICS where TABLE_NAME = 'EMP' and OWNDER = USERDie Statistiken werden hierbei von der Oracle DB selbst erstellt. Diese Statistiken lassen sich allerdings auch mit PLSQL erstellen:
DBMS_STATS.GATHER_FIXED_OBJECTS_STATS;3. Optimizer - Joins
Hierbei handelt es sich NICHT um Joins, die in den klassischen SQL Statements verwendet werden. Es gibt hier mehrere Arten dieser Joins:
-
Sort-Merge Joins
-
Hash Joins
-
Nested Loops
-
Star Joins
3.1. Nested Loop
Der Nested Loop besteht aus zwei verschachtelten For-Schleifen. Hierbei wird die innere Schleife nur einmal durchgeführt. Dieser ist besonders praktisch, wenn es um kleine Datenmengen geht.
BEGIN
FOR outer_loop IN (SELECT deptno FROM dept)
LOOP
FOR inner_loop IN (SELECT empno FROM emp WHERE deptno = outer_loop.deptno)
LOOP
<..>
RETURN;
END LOOP inner_loop;
END LOOP outer_loop;
END;3.2. Star Join
-
Wird vor allem bei Data-warehouse verwendet
-
Eine große, zentrale Tabelle (Fact Table) wird mit mindestens 2 weiteren kleinen Tabellen gejoint
3.3. SOrt-Merge-Join
-
Tabellen werden bereits beim Joinen Sortiert
-
Where Klausen werden beim Full-Table Scan evaluiert
-
Die kleinere Tabelle soll zuerst gelesen werden
-
Diese sind für große Datenmengen gut geeignet
Ein Nachteil ist der Sortiervorgang während des Joins, welcher extra Zeit in Anspruch nehmen kann.
3.4. Hash Join
-
gut für große Datenmengen geeignet
-
schneller als Sort-Merge Joins
-
wird nur von CBO unterstützt
-
funktioniert nur auf Equi-Joins
Aus kleineren Tabellen wird eine Hashtable (Hashmap, Dictionary, Key-Value-Pair, …) in Memory gespeichert. Danach werden die Join-Columns mit den Werten der kleineren Tabelle verglichen.
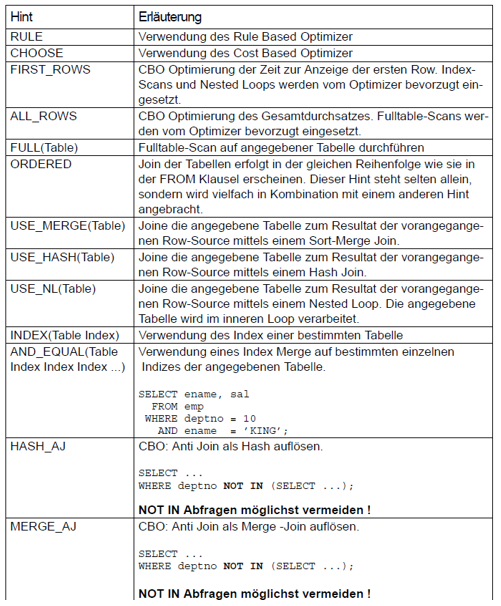
4. Optimizer - Hints
Hints sind Kommentare, die in einer Query eingebaut werden können. Hiermit gibt man dem Optimizer vor, dass er sich an gewisse Regeln halten sollte, wie z.B. man möchte CBO oder RBO verwenden, welche Join-Strategie verwendet werden sollte, etc. Der Optimizer muss diese Hinters allerdings nicht einhalten. Diese dürfen auch einfach ignoriert werden. Aus diesem Grund muss nach dem Ausführen einer Query überprüft werden, ob der Optimizer diese Hints ignoriert hat.
5. Explain Plan
Der Optimizer erstellt für jede Query einen Ausführplan. Falls eine Query mehrere Male in kurzer Zeitabfolge ausgeführt wird, bleibt der Plan gleich. Diesen Plan kann man sich mit folgenden SQL Statement anschauen:
EXPLAIN PLAN FOR SELECT / UPDATE / DELETE / INSERTAlle Pläne werden in der View V$ALL_SQL_PLAN gespeichert.